On job-hunting in 2024 as a machine learning engineer
One Sunday in early December, I celebrated my birthday by slicing into some chocolate cake from a local bakery. A few hours later, my inbox contained a lovely birthday surprise: a calendar invite to discuss my layoff from Spotify. Yay!
For those who don't know me: I am a machine learning engineer with 15 years of experience in data science and 12 years of experience working on end-to-end systems and workflows using machine learning models. During my career I have mostly focused on recommender systems, although I most recently contributed to development of the second generation of Spotify's machine learning framework, Hendrix.
Since that birthday surprise, I've been speaking with companies about opportunities in ML engineering and ML infrastructure. This post describes my experience and attempts to generalize them to some broader thoughts about the labor market for professionals working in the rapidly-heating ML / AI sub-space of the tech industry.
The details of my job serach
I define a "conversation" as any discussion with a company re: employment as a machine learning engineer. By that measure, I held 39 conversations between mid-December 2023 and late February 2024. Of these, 17 did not advance beyond the recruiter or hiring manager call for a range of reasons on both sides of the discussion. Most of these conversations started with cold outreach on my part, and I don't feel that any of these 17 roles represented a phenomenal opportunity for me.
I had 9 on-sites. I ended two of these early because of fit issues. I tried to remain thoughtful and considerate of others during my chats, but with these two companies I didn't feel my approach was reciprocated. Zero regrets about ending those discussions early.
Four of these 9 on-sites led to an offer. One of them involved stock compensation, with a verbal agreement to discuss cash compensation after a fundraising round. Funnily enough, one of these four offers started as a rejection, then flipped back after the other candidate reneged on a signed offer. Salacious stuff!!
Throughout these conversations I tracked my level of interest alongside other company details. You can find those in the table below.
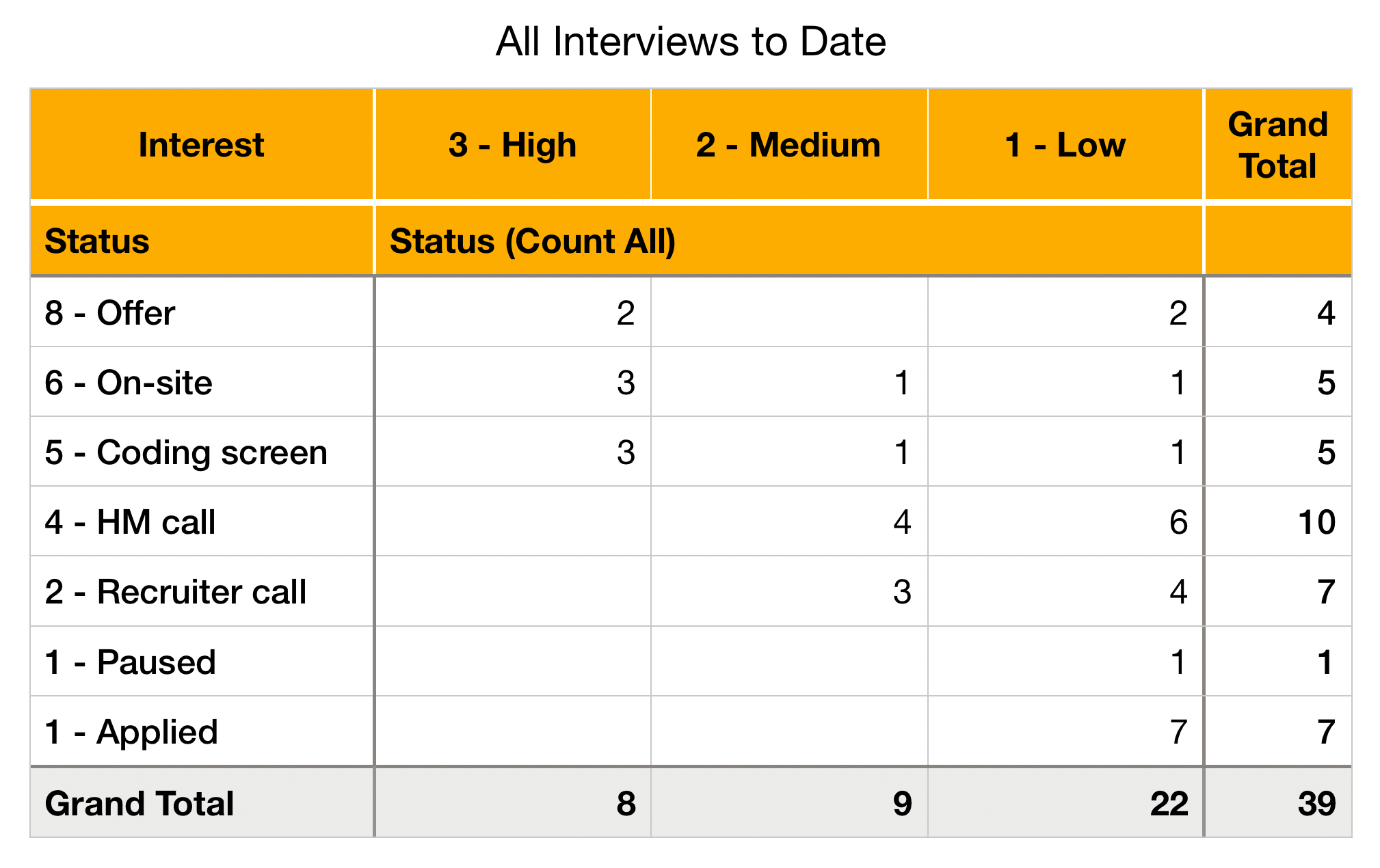
My "surface area for luck" and the importance of reverse interviewing
The above table doesn't fully capture the "confidence in interest" which I recorded for various opportunities. Interviews are conducted by parties with asymmetric information. I know about my strengths and weaknesses, my goals and desires. The hiring team similarly envisions responsibilities and compensation for each hire. I therefore carried two goals into each conversation: (1) demonstrate my skills and potential, while (2) collecting information on the role and updating confidence in my interest levels. Each conversation started with a "low" confidence score and a "medium" level of interest, and both values evolved as the hiring team and I swapped information about each other.
In the same way a company might quickly reject a candidate who doesn't fit the role, I tried to quickly stop conversations which seemed misaligned on either side. This is clearly visualized by the distribution of conversations from the bottom right of the table (low-interest conversations which stopped early) to the upper left of the table (high-interest conversations reaching later stages). I hope I haven't made this point in a hubristic way! Rather, after years on both sides of the interviewing table, I understood the value of both my personal time and the interviewing company's time.
In a way, I was forced to take this approach after deciding early on to maximize my surface area for luck. We're all familiar with The Great One's pithy quote on his offensive skill: "you miss 100% of the shots you don't take."
{kind=link}

I also appreciate Sam Altman's framing:
“Give yourself a lot of shots to get lucky” is even better advice than it appears on the surface. Luck isn’t an independent variable but increases super-linearly with more surface area—you meet more people, make more connections between new ideas, learn patterns, etc.
I tried to maximize my luck by maintaining a full, broad funnel of opportunities, which I then evaluated through the lens of my career goals. My layoff from Spotify presented obvious challenges, but it also accelerated my timelines during an exciting moment in the history of artificial intelligence. It feels like the right moment to prioritize these goals:
- Building for impact. Over the last two years I've been fortunate enough to work at large, publicly-traded tech companies. That said, the work offered uneven impact. Projects with lower impact were surprisingly common, leaving me demotivated at times during a third of my waking hours. Let's not get it twisted - I don't want to claim a perfect success rate on technical projects! That said, clear misalignments between company vision, technical strategy, and tactical execution can waste a person's time and potential for impact. I therefore optimized for consistently-high impact with my new team.
- Growth and learning. In recent years I've started seriously developing theories for effective technical and business strategy. At larger companies, though, I'm unable to test these theories - instead, I was expected to execute projects defined within a strategy designed by committee. Opportunities to identify and "own" cross-functional initiatives only emerge after years of experience and accumulation of capital within large, vertical organizations. These teams cautiously deliver changes to avoid harming revenue streams. At this point in my career, however, I feel I cannot afford any delays in developing this experience.
- Culture, culture, culture. Becoming a father has kicked my ass. I've had to humble myself as two different baby boys pooped, wet-burped, and fussed me into submission. They've fortunately grown up healthy and happy, and I've benefitted from navigating this experience with greater humility and self-assuredness. Now, I'm confident enough in my desire and abilities to build a product from the ground up. I'm also prepared to learn from my mistakes and other difficult lessons along the way. I therefore wanted to partner with folks with a similarly humble, self-assured outlook on product development.
I spent more effort reverse-interviewing companies than during any of my other job searches. This was the first time I trusted myself enough to turn down opportunities that did not align with my goals. Similarly, I tried to remain pragmatic and realistic when rejected by a team. Even if only a handful of my conversations led to offers, they allowed me to hone my pitch and learn new lessons.
A monopsonistic labor market
I learned a key lesson early on in how I misunderstood compensation in today's market. Market pay has seemed to slide downward for everyone. We are now operating in a monopsonistic labor market, where most employee demand concentrates among very few large tech firms. Anecdotally, these firms seem to be applying pressure onto compensation packages by either downleveling applicants or "accidentally" decreasing total compensation package offers:
Once you’re done with team matching, things get dicey. Your recruiter will make you a lowball offer that’s often $50k or more (!!) below the average TC on levels.fyi. Moreover, you usually just get a couple of days to make a decision. If you were down-leveled, your lowball offer may include a small signing bonus as a consolation prize. [...] If you have other offers, they will apologize for the lowball offer, citing that it’s “automatic numbers from our computer” and raise the numbers by $100K or more (in first year’s TC).
I decided to compromise on compensation during this search as a result, throwing out my strict requirements after observing this behavior and hearing about it from several candidates outside of Meta.
As a consequence of this monopsony, large tech companies are also swimming in applicants. Several large companies took weeks in responding to my outreach, and others ghosted me after I entered the funnel (and even completed a few rounds). This held true even for warm introductions,suggesting that these companies have ample hiring supply after 18-24 months of endless layoffs. My most successful BigCo loop with a Magnificent Seven company ended after I struggled with a question on managing hash collisions. The question was posed towards the last five minutes of a 2-hour block, and I'm not particularly fussed about failing. I knew the information, but couldn't access the neurons containing it after a long run of child care and interviewing. That said, I'm surprised to learn that this was the deciding factor in my rejection. Clearly, this company can afford to pass on me, since many other applicants possess both a similar (or stronger) background and the ability to answer this question correctly in an interview.
I ultimately pivoted my search when I realized my opportunity cost for accepting any given role would likely fall below high growth compensation packages for ML / AI engineers during the pandemic boom. As large tech companies slim down on headcount, there will be fewer total packages reaching $400,000+ for senior and staff engineers. These openings will be contested far more aggressively than prior to 2020. Instead of packing myself into this funnel and grinding out interview practice, I decided to prioritize other values in my search.
Startups offered many opportunities to help launch ML / AI competencies with high business impact. We are all familiar with the hottest AI startups of the moment, but there's also a layer of companies thoughtfully applying machine learning to underserved domains. Beyond teams like Mistral, Perplexity, and Rabbit you'll find contract intelligence products with excellent product-market fit and computer vision projects at growing insurance companies. Groq may revolutionize AI inference with LPUs, but similar opportunities exist to, say, evolve medical devices through software and data.
There's one wrinkle to watch for as you navigate ML / AI opportunities at startups: AI-focused startups are aggressively prioritizing applicants experienced with emerging AI tools.These small teams have ambitious goals to build AI agents, domain-specific foundational models, and other products leveraging RAG and LLM evaluation techniques. This space is _very_dynamic, presenting many opportunities for tenacious and interested folks to dive in and develop hands-on experience quickly. But you might encounter bumps along the way - I know I certainly did.
What's next
Did my broad funnel ultimately work? Well, during this search I aggressively accepted cold inbound requests from recruiters and hiring teams for the first time. Not only did I respond to random emails and LinkedIn messages, I hassled these folks for responses! One of these messages introduced an exciting opportunity which I've now joined as a founding engineer. It's the first time in a decade that I've joined a team with fewer than 10 employees. Recounting this fact admittedly causes me a brief flash of terror. I strongly believe, though, this opportunity fits with my experience, desired culture, and career goals, and I'm thrilled to build within the rapidly-evolving AI infrastructure space.
For the first time in years, I'm excited and uncertain about my next role. I'm energized by the realization that I'm starting a new chapter of my career. I hope to write more often as I embark on this journey, and I appreciate your company and thoughts on the first step of this new path.
Some caveats
I'll close by stating a few points bluntly:
- There are many incredibly talented and experienced engineers looking for their next opportunity.Insofar as my personal experience and strategy can generalize to others, I hope other folks on the job market find them helpful.
- I am endlessly fortunate to work in a high-paying, high-demand specialty within the tech sector.So much of my experience might not generalize too far beyond ML / AI work into other tech roles. I understand that fact. Regardless, I hope I've clarified one area of the market and provided comfort for others searching for their next opportunity.
- I am similarly fortunate to have the opportunity to spend several months finding the best role for my needs.This would not have been true of me years (or even months) ago, and I acknowledge this reality does not exist for anyone.
In light of the above, I want to offer some concrete help:
- I will happily connect you to opportunities you might find interesting.My broad funnel approach benefitted greatly from the generosity of many other folks. If you see a shared connection on LinkedIn, don't hesitate to ask me for a warm introduction. I would be thrilled to provide one for you!
- I am happy to review resumes or provide mock interviews to any ML/AI or data engineers on the job market. I've sat on both sides of the hiring table in many situations, and would love to use that experience to help folks. You can use this link to book a chat with me. I cannot promise profound insight, but I will happily pay forward the support I received during my job search.
Gratitude
Let's end on a note of gratitude.
None of this would have been possible without many incredible people: Ravi Mody, James Kirk, Jeremy Jordan, Deron Aucoin, Ben Deaton, Jowanza Joseph, Vicki Boykis, Karla Goodreau, Fiona Siseman, Brett Vintch, Abdullah Mobeen, Pedro Alcocer, Oscar Rodriguez, Ivan Aguirre, Navid Zolfaghari, DJ Patil, Adam Boscarino and Hal Baseman. Thanks for the thoughts, memes, introductions, and real talk.
Regina, Xander and Lennox deserve their own line. Enormous hugs and kisses to you - none of this would've been possible without you. Prepara, Ale!!