A survey of ACM RecSys 2018
During October I attended the 2018 edition of the ACM Recommender System Conference, or RecSys, in Vancouver. For one week, over 800 participants from various corners of industry and academia presented results and discussed trends in recommender system design. As a first-time attendee, I was impressed by
- the clever and sophisticated approaches employed by RecSys attendees to solve personalization tasks, and
- the willingness of these attendees to discuss their clever and sophisticated approaches in great detail.
So: many opportunities to learn about the state-of-the-art in recommender systems! Below, I briefly survey these trends and point to further references. This survey is most useful if you're familiar with fundamental approaches to recommender systems. If you'd like a crash course, I recommend our introduction to matrix factorization at iHeartRadio.
Contextual bandits were very popular
Spotify, Pandora, Netflix and Google all presented work on contextual bandits. Like multi-armed bandits, these models use historical data to select one of several possible actions in response to the current state; contextual bandits also add information about the current state of the system - say, data about the user's preferences for music or movie genres - to the decisionmaking process.
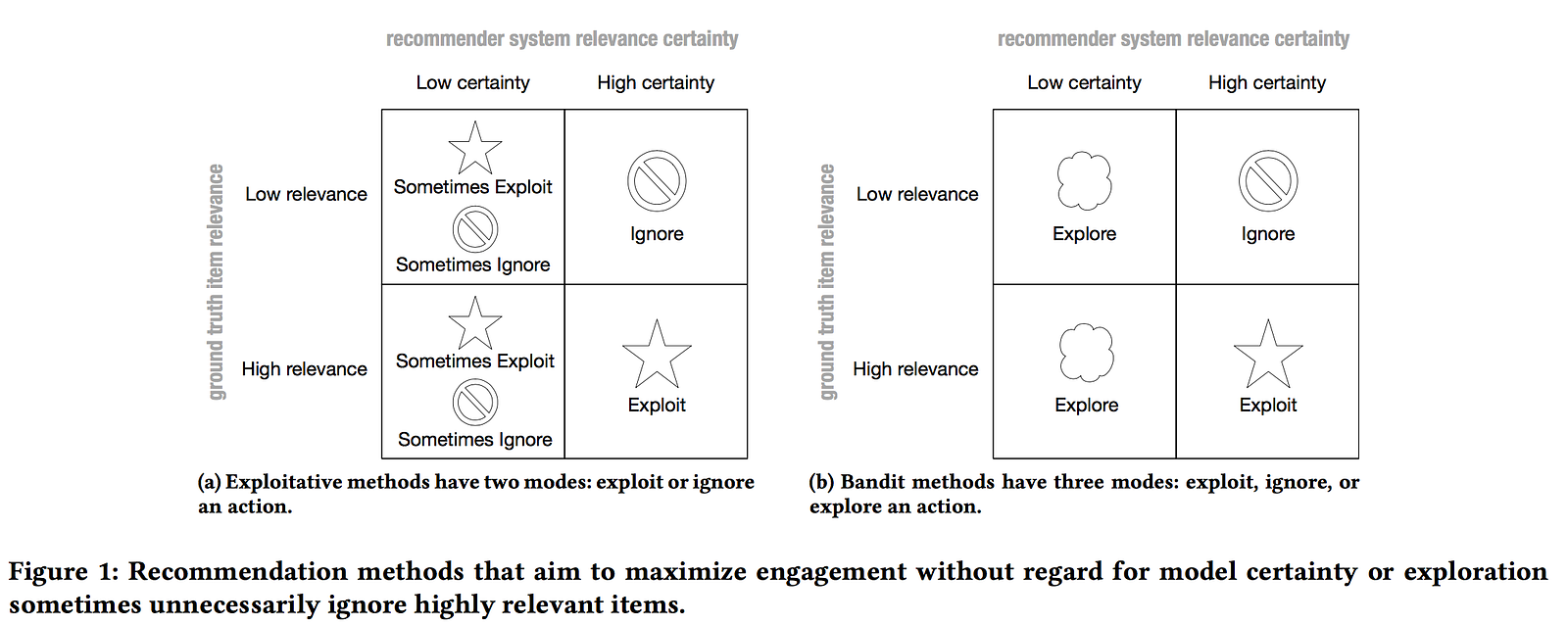
I loved this chart from Spotify's work on Bart (which I discuss in greater detail below). Bandits are appealing because they can explore spaces and develop new action policies where a model is uncertain about item relevance. Exploring is expensive, and policy learning is intractable in large action spaces, so all of the applications at RecSys were limited to small actions.
Three companies - Spotify, Pandora, and Netflix - presented in some detail on their bandit applications to the home screen. Pandora walks us through an example, where they re-shuffle content "modules" on the home screen based on observed user preferences.

All three companies take the same approach to model development. This Pandora slide again provides an example.

This strategy generally holds across all three cases: train multi-armed bandits offline, evaluate using mean reciprocal rank - a metric for measuring ranking quality - then confirm using A/B testing. Replace "mean reciprocal rank" with "inverse propensity score" (see the introduction here for details), and you have the same methodology used by Spotify and Netflix: train and evaluate bandits offline, confirm online via A/B test.
In one of my favorite talks from the conference, Spotify presented Bart, a new framework for producing recommendations with explanations using contextual multi-armed bandits. They applied Bart to the task of ordering "shelves" (what Pandora called "modules") on the app home screen. Offline evaluation and online experiments show that explained recommendations outperform random orderings and orderings produced by logistic regression.
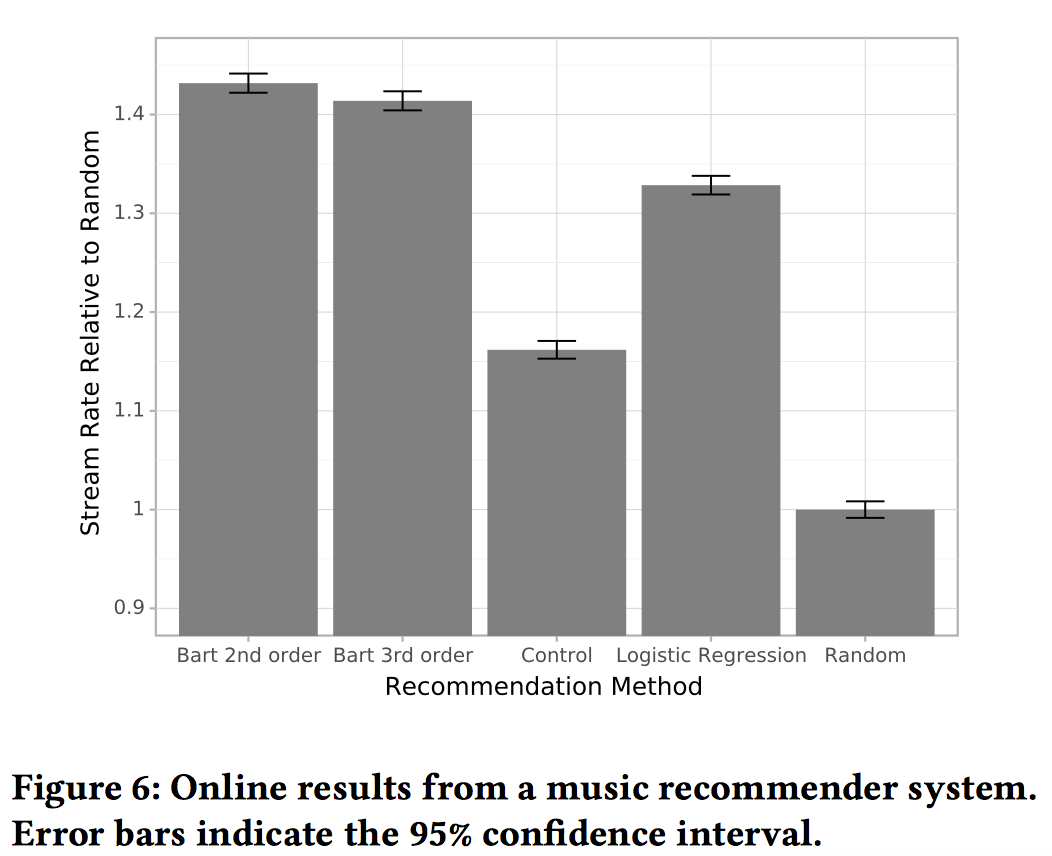
Interestingly, Bart relies on factorization machines (2nd-order and 3rd-order). More on this later.
Netflix applied contextual bandits to a very unique problem: given video content and user context, what is the optimal artwork to display for that content on the user's home page?

I thought this was a clever use of bandits: train a bandit for each show, learn which image maximizes engagement conditional on context, then show that image. At Netflix's scale - a 12-figure company with tens of millions of subscribers - such a project could lead to millions in new revenue solely through a single-digit percentage lift in engagement. That's a cool - if very unique - opportunity.
If you would like more detail on their work, I recommend a previous Medium post describing this work in detail.
Factorization machines: still popular
Factorization machines (FMs) are a staple at RecSys. That's not very surprising! They can be thought of as a generalization of matrix factorization (which we have blogged about before) that accepts metadata along with user-item interactions to tackle varied problems. At RecSys 2016 Criteo updated factorization machines with "fields", their term for pairwise tensor interactions. Spotify also uses FMs in Bart, as mentioned above, and some other folks presented FM-related work this year as well.
One team finished in 3rd place in Spotify's playlist continuation challenge with a two-stage approach relying in part on FMs. All of their code lives in Jupyter notebooks, and the paper is gated, but they also relied on LightFM for their submission.


Anecdotally, several teams also described to me their successful experiments with LightFM. These groups are operationalizing their prototypes now.
Offline and evaluation metrics are 🆗👌
A sub-domain of recsys research focuses on counterfactual evaluation, or the evaluation of learned models or policies using logged data. I was excited to learn more about this work, and there were some promising developments presented in Vancouver this year.
Inverse propensity scoring, as mentioned before, seems to be the go-to for evaluating contextual bandits. I've never worked with IPS before, but Yang et al. has a nice discussion in the context of evaluating recommenders with missing-not-at-random implicit feedback.

This work also cites Schnabel et al., which nicely reviews techniques for debiasing training data.
One of my hobby horses is the use of evaluation metrics to understand algorithm performance before online experimentation, and RecSys did not disappoint here. A first work by Valcarce et al. surveyed the resiliency of various metrics to sparsity and popularity biases along two paths: evaluate these metrics (precision, recall, MRR, etc) at K=100, and evaluate NDCG for various settings of K. This was a clever analysis with some clear takeaways, although they may not generalize.
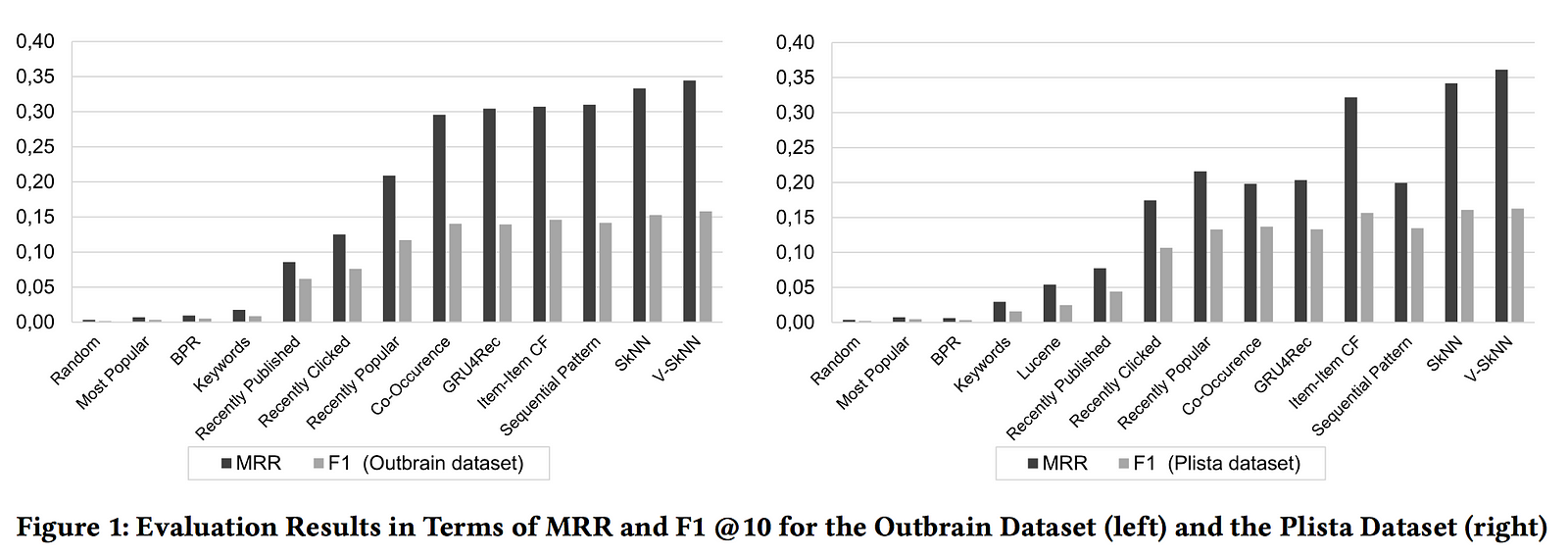
Another paper reviewed a whole collection of streaming algorithms on two news recommendation datasets (Outbrain and Plista). I really appreciated this paper by Jugovac et al. for its exhaustive list of recommender algorithm options in streaming contexts, with performance evaluated using mean reciprocal rank and F-score@10.
I also enjoyed Netflix's work on calibrated recommendations. Steck proposes re-ranking recommender results using the KL-divergence between the genre distribution of the user's activity and the genre distribution of the recommender's output.
slide here
There are clear applications to some ongoing projects at iHeartRadio - most notably, Your Weekly Mixtape.
Lots of work relied on autoencoders
Autoencoders are an extremely powerful class of algorithms for learning representations without labels (that is, on unsupervised data). As an introduction, our director of data, Brett Vintch, has previously applied them to the construction of coherent playlists.
Here's a laundry list of the various projects we encountered that depended on autoencoders in some form:
-
Towards Large Scale Training Of Autoencoders For Collaborative Filtering
-
Item Recommendation with Variational Autoencoders and Heterogenous Priors
-
A Collective Variational Autoencoder for Top-N Recommendation with Side Information
-
MMCF: Multimodal Collaborative Filtering for Automatic Playlist Continuation
Industry talks I enjoyed
As a data person employed in industry, I like to attend industry talks because they cover industry challenges - adopting frameworks, applying business logic, and accounting for changes in user behavior - that I am responsible for solving in industry. On that note, I really enjoyed these presentations:
-
Netflix: calibrated recommendations and artwork recommendations.
-
realtor.com on using fast.ai and PyTorch for transfer learning using autoencoders, especially applied to search re-ranking. As far as I know, slides are not publicly available, but they might go up soon.
-
Slack on developing models with strict privacy boundaries. Bonus: they use really simple algorithms.

RecSys 2018: A+ would recommend
All in all, RecSys 2018 was an extremely rewarding experience. A healthy presence from both academic and industry researchers produced a slate of presentations with a healthy mix of cutting-edge algorithms and production-grade systems. I had an opportunity to reinforce my understanding of fundamental recommender systems concepts and learn about the latest trends in the space. The 2019 edition will be hosted in Copenhagen, and the call for submissions closes in April - I highly recommend participating, whether you are interested in learning something new or presenting your most recent work.
Lastly, if you are interested in learning more about music recommendations or building a streaming music service, make sure to check out open positions on our jobs page!